



版权说明:本文档由用户提供并上传,收益归属内容提供方,若内容存在侵权,请进行举报或认领
文档简介
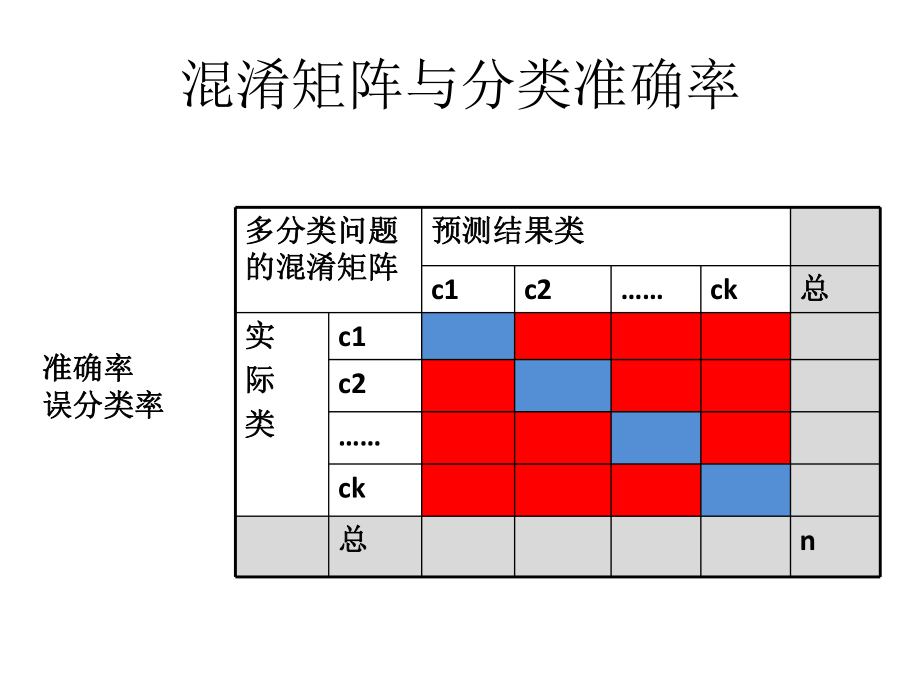
1、分类器的评估张英张英混淆矩阵与分类准确率多分类问题多分类问题的混淆矩阵的混淆矩阵预测结果类预测结果类c1c2ck总总实实际际类类c1c2ck总总n准确率准确率误分类率误分类率分类模型的评价指标1. 准确率与误分类率准确率与误分类率准确率准确率 =(tp+tn) )/(tp+fn+fp+tn)误分类率误分类率=(fn+fp)/(tp+fn+fp+tn)真正率(灵敏度)真正率(灵敏度) =tp/(tp+fn)真负率(特指度)真负率(特指度) =tn/(fp+tn) 假正率假正率 =fp/(fp+tn) 假负率假负率 =fn/(tp+fn)二分类问题二分类问题的混淆矩阵的混淆矩阵预测结果类预测结果类
2、+-总总实实际际类类+ tp fntp+fn- fp tnfp+tn总总tp+fpfn+tntp+fn+fp+tn不平衡分布类二类分类问题的混淆矩阵预测结果类+10-90实际类+5+(tp)3+-(fn)2-95-+(fp)7(tn)88误分类率:误分类率:9% 真正率:真正率:60%评估指标评估指标2. 精度精度 P=tp / (tp+fp) 3. 召回率(真正率、灵敏召回率(真正率、灵敏度)度) R=tp/(tp+fn)4.FSCORE 精度和召回率精度和召回率 的调和均值:的调和均值:召回率和精度的权重相同:召回率和精度的权重相同: F = 2RP/(R+P)将召回率的权重设为精度的将召
3、回率的权重设为精度的倍倍:二分类问题的二分类问题的混淆矩阵混淆矩阵预测结果类预测结果类+-总总实实际际类类+ tp fntp+fn- fp tnfp+tn总总tp+fpfn+tntp+fn+fp+tn评估指标二分类问二分类问题的误分题的误分类代价类代价预测结果类预测结果类+-总总实际实际类类+C(+,+) C(+,-) C(+,+)*TP+C(+,-)*FN-C(-,+) C(-,-) C(-,+)*FP+C(-,-)*TN误分类代价误分类代价 (成本或收益)(成本或收益) 误分类代价对称误分类代价对称C(+,+)=C(-,-)=0C(+,-)=C(-,+)=1误分类代价不对称误分类代价不对称
4、关注预测为正类 成本角度 收益角度二分类问题的二分类问题的混淆矩阵混淆矩阵预测结果类预测结果类+-总总实实际际类类+ tp fntp+fn- fp tnfp+tn预测性能评估指标的选择预测性能评估指标的选择 平衡分布类,对称误分类代价 准确率、误分类率,精度误分类率,精度 不平衡分布类,对称误分类代价 精度,召回率,精度,召回率,FSCORE 不对称误分类代价 成本或收益成本或收益模型评估方法Hold方法方法将数据分成训练集和验证(测试)集,一般按照将数据分成训练集和验证(测试)集,一般按照2:1比例划分,以验证集指标进行评估;比例划分,以验证集指标进行评估;多次随机采样多次随机采样进行进行N
5、次上述(次上述(1)的随机采样,然后计算)的随机采样,然后计算N个测个测试精度的平均值试精度的平均值自助法(自助法(bootstrap)(最常用的(最常用的.632自助法)自助法)进行进行N次有放回的均匀采样,获得的数据集作为训次有放回的均匀采样,获得的数据集作为训练集,原数据集中未被抽中的其它观测形成验证练集,原数据集中未被抽中的其它观测形成验证集。可重复集。可重复K次,计算准确率:次,计算准确率:模型评估方法交叉验证交叉验证 数据集小的时候,可将数据集分成数据集小的时候,可将数据集分成K个不相个不相交的等大数据子集,每次将交的等大数据子集,每次将K-1个数据集作为训个数据集作为训练集,将练
6、集,将1个数据集作为验证(测试)集,得个数据集作为验证(测试)集,得到到K个测试精度,然后计算个测试精度,然后计算K个测试指标的平均个测试指标的平均值。值。留一交叉验证:留一交叉验证:K=N;分层交叉验证:每个部分中保持目标变量的分分层交叉验证:每个部分中保持目标变量的分布。布。不同分类器预测准确度差异的显不同分类器预测准确度差异的显著性检验著性检验 T检验(自由度为检验(自由度为K-1)以交叉验证为例(以交叉验证为例(k为验证集观测分折数):为验证集观测分折数):相同验证集:相同验证集:不同验证集:不同验证集:分类器预测准确度分类器预测准确度置信区间置信区间分类器预测分类器预测真正真正准确度
7、准确度p=其中:N:验证集观测个数; acc:基于当前验证集分类器的准确度;ROC曲线(receiver operating characteristic) 曲线下方面积越大,模型越好,即曲线与曲线下方面积越大,模型越好,即曲线与y轴正向的夹角越小轴正向的夹角越小越好。越好。真正率真正率假正率假正率二分类问题二分类问题的混淆矩阵的混淆矩阵预测结果类预测结果类+-总总实实际际类类+ tp fntp+fn- fp tnfp+tn总总tp+fpfn+tntp+fn+fp+tn制作ROC曲线验证集共有验证集共有10个观测,其中正类(个观测,其中正类(P类)类)5个,负类(个,负类(N类)类)5个个将验
8、证集各观测按照预测为正类的概率降序排列,每个观测计算对应将验证集各观测按照预测为正类的概率降序排列,每个观测计算对应的真正率和假正率,形成一个点。的真正率和假正率,形成一个点。提升图假定:假定: 目标变量的取值为目标变量的取值为GOOD 和和BAD N 为验证集观测个数;为验证集观测个数; RGOOD为验证集目标变量取为验证集目标变量取 值为值为GOOD的观测个数;的观测个数; p_good为验证集目标变量为验证集目标变量 预测为预测为GOOD的概率值;的概率值;验证集的混验证集的混淆矩阵淆矩阵预测预测结果类结果类goodbad总总实实际际类类good tp fnRGOODbad fp tnR
9、bad总总N绘制提升图1.将验证集各观测按照将验证集各观测按照p_good降序排列降序排列,等分成等分成10组。组。2.以以10个分组为横坐标个分组为横坐标 以下指标分别为纵坐标:以下指标分别为纵坐标:%response:每组中实际为:每组中实际为GOOD的观测个数占本组总的观测个数占本组总个数的比例个数的比例;%captured response:每组中实际为每组中实际为GOOD的观测个数的观测个数占占RGOOD的比例的比例;%cumulative response:前面各组中实际为前面各组中实际为GOOD的观测的观测个数占前面各组总个数的比例个数占前面各组总个数的比例%cumulative
10、 captured response:前面各组中实际为前面各组中实际为GOOD的观测个数占的观测个数占RGOOD的比例。的比例。lift value=使用模型以后的使用模型以后的% response/ 不使用任何模不使用任何模型进行决策的型进行决策的% response提升图某公司发送了某公司发送了1000封广告邮件,有封广告邮件,有200个客户响应了邮件(即由于个客户响应了邮件(即由于收到邮件而在该公司产生了消费行为)。每个收到邮件而在该公司产生了消费行为)。每个10分位(分位(100个观测)的个观测)的响应者个数根据对验证数据集的计算得到。响应者个数根据对验证数据集的计算得到。决策阈值选择 根据每个观测预测为每个目标类的根据每个观测预测为每个目标类的概率决定该观测的目标类值。概率决定该观测的目标类值。 对二分类:对二分类: 理论阈值理论阈值p=1/(1+1/B) B=C(-,+)/C(+,-)根据提升图和实际业务背景选择根据提升图和实际业务背景选择合适的分组比例。合适的分组比例。 根据分组比例决定最终决策阈根据分组比例决定最终决策阈值。值。提高分类准确率技术组合分类组合分类方法 有放回抽样产生多个样本 装袋:多数表决决定最终结果 提升(ada boost) 随机森林:多颗决策树,随机属性选择组合方法 联合方法
温馨提示
- 1. 本站所有资源如无特殊说明,都需要本地电脑安装OFFICE2007和PDF阅读器。图纸软件为CAD,CAXA,PROE,UG,SolidWorks等.压缩文件请下载最新的WinRAR软件解压。
- 2. 本站的文档不包含任何第三方提供的附件图纸等,如果需要附件,请联系上传者。文件的所有权益归上传用户所有。
- 3. 本站RAR压缩包中若带图纸,网页内容里面会有图纸预览,若没有图纸预览就没有图纸。
- 4. 未经权益所有人同意不得将文件中的内容挪作商业或盈利用途。
- 5. 人人文库网仅提供信息存储空间,仅对用户上传内容的表现方式做保护处理,对用户上传分享的文档内容本身不做任何修改或编辑,并不能对任何下载内容负责。
- 6. 下载文件中如有侵权或不适当内容,请与我们联系,我们立即纠正。
- 7. 本站不保证下载资源的准确性、安全性和完整性, 同时也不承担用户因使用这些下载资源对自己和他人造成任何形式的伤害或损失。
最新文档
- 秋季呼吸道传染病防治知识:海运篇
- 房地产拓客十二式:拓展高端客户
- 妊娠期高血压疾病孕期锻炼试卷
- 经济作物种植承包合同
- 2023-2024学年浙江省杭州市七年级下册数学期末模拟卷
- 冷疗法在骨科慢性疼痛管理中的效果
- 医院感染控制经验分享培训
- 塑料加工废水处理培训资料
- 业主收楼承诺书医疗社区
- 公司和个人签合同范本共
- 霉菌的形态结构(课堂PPT)
- 小学五年级下册综合实践活动.学做简单的家常菜---(21张)ppt
- GB∕T 309-2021 滚动轴承 滚针
- 《苯的结构与化学性质》教案(共4页)
- 试验检测项目及收费标准要点
- 赞美诗歌400首全集
- 江苏省中小学教育技术装备标准高级中学分册
- 各种标准法兰尺寸对照
- 不同温度下硫酸溶液浓度和比重对照表
- 影响降膜蒸发器中成膜原因分析
- 纯水机日常维护保养点检记录表
评论
0/150
提交评论